
数据分析
numpy
数组中的轴:
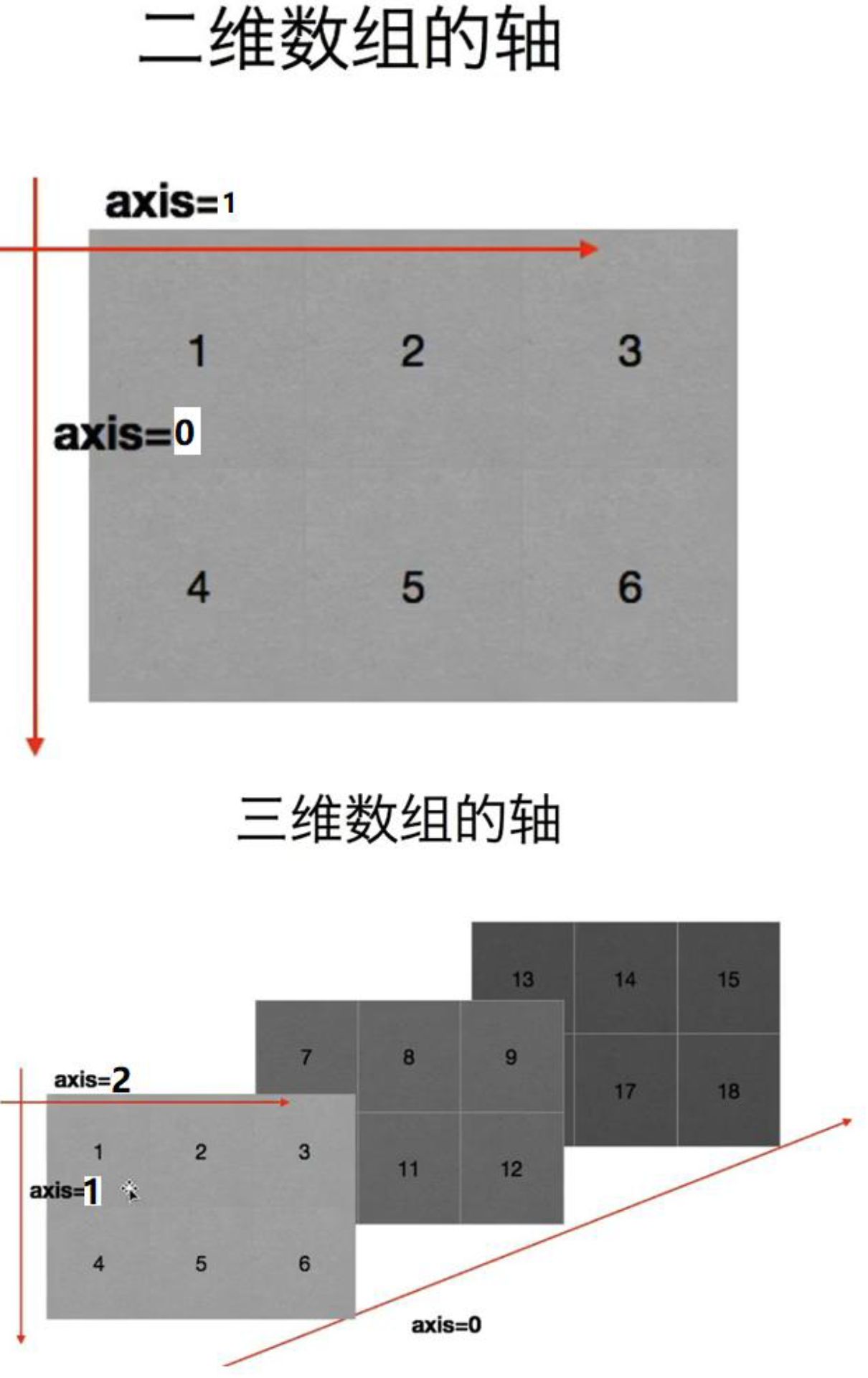
其实很好理解,越外面循环的 axis 值越小。
一些值得注意的特性:
1 | import numpy as np |
改变多维数组的形状(具体细节谷歌搜索):
1 | np.swapaxes() # 可用作二维矩阵的转置 |
一个常用的数据集网站: https://www.kaggle.com/
一个英国和美国 youtube 一千多个视频的点击、喜欢、不喜欢、评论数量的 csv :
https://www.kaggle.com/datasets/datasnaek/youtube/data
numpy 读取数据 np.loadtxt(),需要关注的参数:
- dtype
- delimiter, 分隔符
- skiprows, 跳过行
- usecols, 读取指定的列、索引、元组类型
- unpack
Pandas
numpy 能够处理数值型数据,但是很多时候,除了数值之外,还有字符串、时间序列等。
Pandas 可以处理 CSV 和文本文件、Microsoft Excel、SQL 数据库和快速 HDF 5 等格式。
Series
Pandas 两个主要的数据结构: Series 和 DataFrame .
Series 是一种类似于一维数组的对象,由一组数据(各种 NumPy 数据类型)及一组与之对应的索引(数据标签)组成。
1 | import pandas as pd |
字典也可以转换为 series, 且 key 和 value 分别对应。
索引建议用 loc, 效率更高。
DataFrame
类似于 excel.
较为灵活的日期功能:
1 | import pandas as pd |
pandas 中使用索引名取某一列:
1 | print(df_obj['A']) # 取出来是 series |
DataFrame 也可以方便地增加、删除列:
1 | # just an example |
常见的 Index 种类:
Index, 普通索引,例如 a, b, c, d, eInt64Index, 整数索引MultiIndex, 层级索引DatetimeIndex, 时间戳类型
DataFrame 也可以用 loc 来拿:
1 | # just an example |
iloc 位置索引:
1 | # DataFrame, iloc 是左闭右开 |
对齐运算
对齐是数据清洗的重要过程,可以按索引对齐进行运算,如果没对齐的位置则补 NaN,最后也可以填充 NaN.
Series 的对齐运算:
1 | import pandas as pd |
DataFrame 的对齐运算:
1 | import pandas as pd |
函数应用
关注 apply 和 applymap 相关资料。
通过 apply 将函数(例如 lambda 函数)应用到列或行上。
通过 applymap 将函数应用到每个数据上。
索引排序
排序默认使用升序排序,ascending=False 为降序排序。
1 | import pandas as pd |
上面代码可以简单地拓展到二维的情形。
按值排序
sort_values() .
处理缺失数据
1 | import pandas as pd |
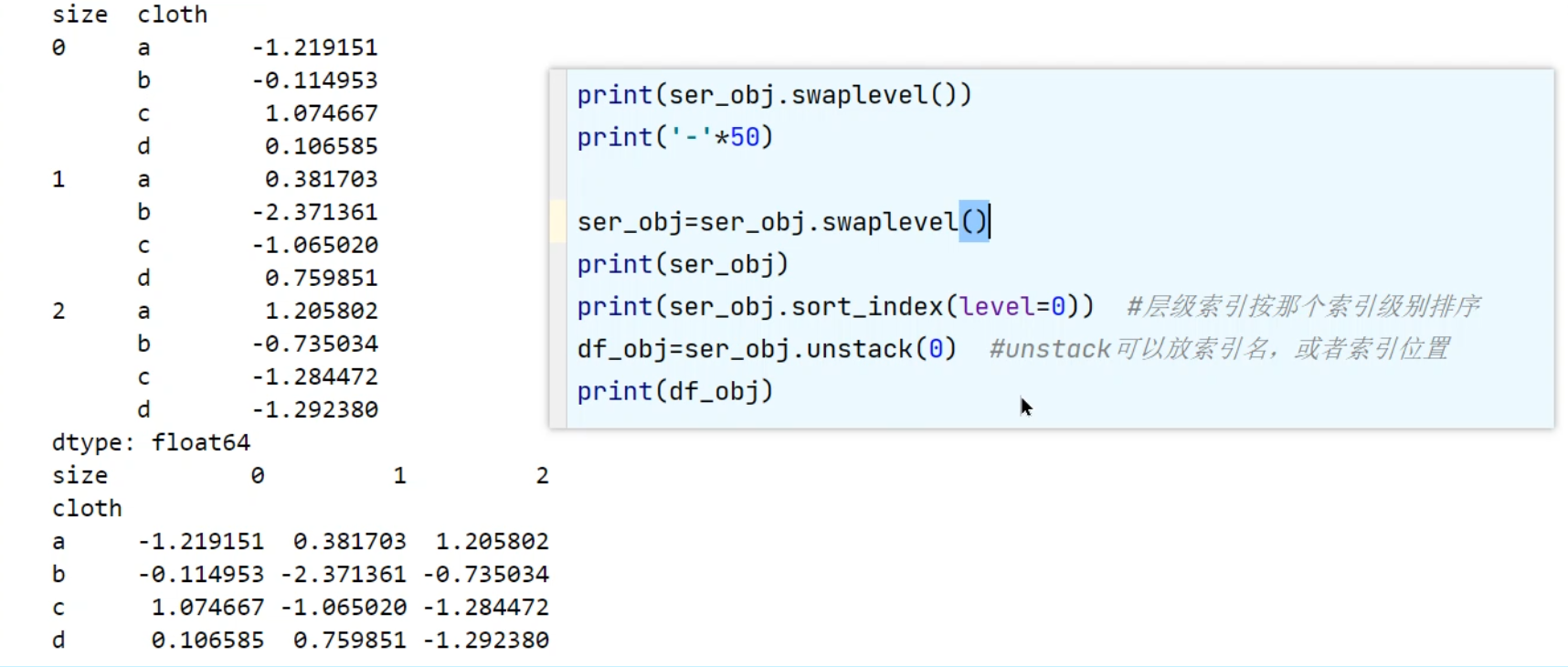
层级索引(hierarchical indexing)
1 | import pandas as pd |
层级索引可以交换层级。
unstack 操作:
统计计算和描述
sum, mean, max, min, describe:
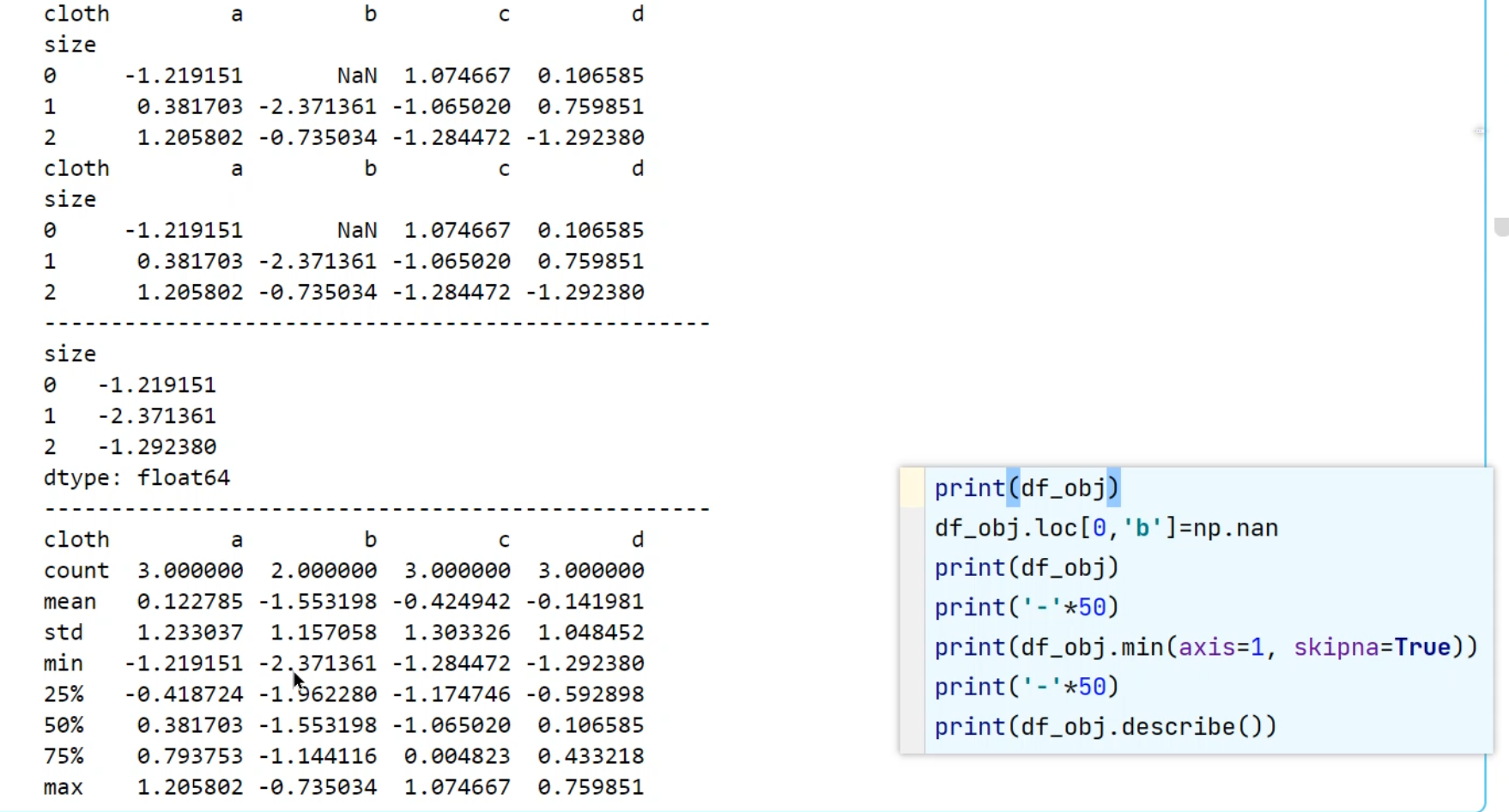
describe 可以用于观察数据分布,是否有异常值等。
其他 pandas 的操作
下面将使用 Jupyter Notebook .
在 Debian 12 上安装 ipykernel :
1 | sudo apt update |
建议使用虚拟环境管理所有数据分析需要的包。
电商数据分析
一般的数据分析流程:
电商平台数据分析:
淘宝用户行为模式分析
 Thanks ᗜ ‸ ᗜ
Thanks ᗜ ‸ ᗜ- ₍ᐢ.ˬ.⑅ᐢ₎







