并发服务器方案
Reactor模型(V1) Socket类:所有与套接字相关的操作都在 Socket 类中,负责套接字的创建与关闭,以及获取套接字。
InetAddress类:所有与地址相关的操作都在 InetAddress 类中,包括 ip 的获取、port 的获取,以及 struct sockadd_in 结构体的操作。
Acceptor类:所有连接相关的操作全部都封装在 Acceptor 中,包括:端口复用、地址复用、bind、listen、accept 操作。
TcpConnection类:只要 accept 函数有正确的返回值,那么就表明三次握手已经建立成功了,那么这条连接就是正常的,就可以创建这条连接。那么数据的收发都可以靠 TcpConnection 这条连接,封装收发数据的函数 send 与 receive 函数。
SocketIO类:是真正底层进行数据收发的类,该类进行执行系统调用 recv/send 操作,进行真正数据的收发。
类图:
代码实现:https://github.com/dropsong/CPP_Code_Eaxmple/tree/master/Reactor_v1
V1 主要是完成了面向对象的封装。
Reactor模型(V2) V1 只实现了非常基础的功能,一个 server 只能服务一个 client. 现在我们尝试加入 epoll.
类图(初版,之后还会有变动):
对应上面的类图写出伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 void loop () _isLooping = true ; while (_isLooping) { waitEpollFd (); } } void unloop () _isLooping = false ; } void waitEpollFd () nready = epoll_wait (); if (-1 == nready && errno == EINTR) { continue ; } else if (-1 == nready) { cerr << "epoll_wait" << endl; return ; } else if (0 == nready) { cout << ">>epoll_wait timeout" << endl; } else { for (int idx = 0 ; idx < nready; ++idx) { if (有新的连接请求进来,并且是读事件) { handleNewConnection (); } else { fd = _evtList[idx].data.fd; handleMessage (fd); } } } } void handleNewConnection () connfd = _acceptor.accept (); if () { } TcpConnection con (connfd) ; _conns.insert (connd, con); addEpollReadFd (connfd); } void handleMessage (int fd) it = _conns.find (fd); if () { it->send (); } else { } }
在面向对象的代码之前,我们先看看面向过程的逻辑 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <errno.h> #include <sys/epoll.h> #include <sys/types.h> #include <sys/socket.h> #include <arpa/inet.h> #include <netinet/in.h> #include <iostream> #include <string> using std::cin;using std::cout;using std::endl;using std::string;void test () int listenfd = ::socket (AF_INET, SOCK_STREAM, 0 ); if (listenfd < 0 ) { perror ("socket" ); return ; } int opt = 1 ; int ret = setsockopt (listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof (opt)); if (-1 == ret) { perror ("setsockopt ip error" ); close (listenfd); return ; } ret = setsockopt (listenfd, SOL_SOCKET, SO_REUSEPORT, &opt, sizeof (opt)); if (-1 == ret) { perror ("setsockopt port error" ); close (listenfd); return ; } struct sockaddr_in serveraddr; memset (&serveraddr, 0 , sizeof (serveraddr)); serveraddr.sin_family = AF_INET; serveraddr.sin_port = htons (8888 ); serveraddr.sin_addr.s_addr = inet_addr ("127.0.0.1" ); socklen_t length = sizeof (serveraddr); if (::bind (listenfd, (struct sockaddr*)&serveraddr, length) < 0 ) { perror ("bind" ); close (listenfd); return ; } if (::listen (listenfd, 128 ) < 0 ) { perror ("listen" ); close (listenfd); return ; } cout << "server is listening..." << endl; int efd = ::epoll_create1 (0 ); struct epoll_event ev; ev.events = EPOLLIN | EPOLLOUT; ev.data.fd = listenfd; ret = ::epoll_ctl (efd, EPOLL_CTL_ADD, listenfd, &ev); if (ret < 0 ) { perror ("epoll_ctl" ); close (listenfd); close (efd); return ; } struct epoll_event *evtList = (struct epoll_event *)malloc (1024 * sizeof (struct epoll_event)); while (1 ) { int nready = ::epoll_wait (efd, evtList, 1024 , 3000 ); if (-1 == nready && errno == EINTR) { continue ; } else if (-1 == nready) { perror ("epoll_wait" ); return ; } else if (0 == nready) { printf (">> epoll_wait timeout!\n" ); } else { for (int idx = 0 ; idx < nready; ++idx) { if ((evtList[idx].data.fd == listenfd) && (evtList[idx].events & EPOLLIN)) { int peerfd = ::accept (listenfd, nullptr , nullptr ); struct epoll_event ev; ev.events = EPOLLIN | EPOLLOUT | EPOLLERR; ev.data.fd = peerfd; ret = ::epoll_ctl (efd, EPOLL_CTL_ADD, peerfd, &ev); if (ret < 0 ) { perror ("epoll_ctl" ); continue ; } printf (">> conn has connected, fd: %d\n" , peerfd); } else { char buff[128 ] = {0 }; if (evtList[idx].events & EPOLLIN) { int fd = evtList[idx].data.fd; ret = ::recv (fd, buff, sizeof (buff), 0 ); if (ret > 0 ) { printf (">>> recv msg %d bytes,content:%s\n" , ret, buff); ret = send (fd, buff, strlen (buff), 0 ); printf (">>> send %d bytes\n" , ret); } else if (ret == 0 ) { printf ("conn has closed!\n" ); struct epoll_event ev; ev.data.fd = fd; ret = ::epoll_ctl (efd, EPOLL_CTL_DEL, fd, &ev); if (ret < 0 ) { perror ("epoll_ctl" ); } } } } } } } close (listenfd); } int main (int argc, char *argv[]) test (); return 0 ; }
TCP 网络编程最本质的是处理三个半事件 :
连接建立 :包括服务器端被动接受连接(accept)和客户端主动发起连接(connect)。TCP 连接一旦建立,客户端和服务端就是平等的,可以各自收发数据。连接断开 :包括主动断开(close、shutdown)和被动断开(read()返回 0)。消息到达 :文件描述符可读。这是最为重要的一个事件,对它的处理方式决定了网络编程的风格(阻塞还是非阻塞,如何处理分包,应用层的缓冲如何设计等等)。消息发送完毕 :这算半个。对于低流量的服务,可不必关心这个事件;另外,这里的“发送完毕”是指数据写入操作系统缓冲区(内核缓冲区),将由 TCP 协议栈负责数据的发送与重传,不代表对方已经接收到数据。
代码:https://github.com/dropsong/CPP_Code_Eaxmple/tree/master/Reactor_v2
重新考虑细节之后,类图如下:
Reactor模型(V3) 为使 V2 代码的 main 函数更加简洁,我们进一步封装:
代码(较 V2 版本改动较小):
https://github.com/dropsong/CPP_Code_Eaxmple/tree/master/Reactor_v3
V2 和 V3 版本其实就是实现了 Basic Reactor Design .
进程、线程通信 引入 我们尝试开发 Reactor 的 V4 版本,即 Reactor with ThreadPool. 要义是将 IO 和计算任务分开。
将 IO 和计算任务分开的必要性:它们的速度不匹配。
我们改进 V3 版本的 TestTcpServer.cc 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 #include "TcpServer.h" #include "TcpConnection.h" #include <iostream> using std::cout;using std::endl;class MyTask { public : MyTask (const string &msg, const TcpConnectionPtr &con) : _msg(msg) , _con(con) { } void process () { _msg; _con->sendInLoop (_msg); } private : string _msg; TcpConnectionPtr _con; }; void onConnection (const TcpConnectionPtr &con) cout << con->toString () << " has connected!" << endl; } void onMessage (const TcpConnectionPtr &con) string msg = con->receive (); cout << ">>recv msg from client: " << msg << endl; MyTask task (msg, con) ; pool.addTask (std::bind (&MyTask::process, task)); } void onClose (const TcpConnectionPtr &con) cout << con->toString () << " has closed!" << endl; } int main (int argc, char **argv) TcpServer server ("127.0.0.1" , 8888 ) ; server.setAllCallback (std::move (onConnection) , std::move (onMessage) , std::move (onClose)); server.start (); return 0 ; }
在上面的代码中,我们发现有必要了解进程、线程间的通信。
eventfd 系统调用 从 Linux 2.6.27 版本开始,新增了不少系统调用,其中包括 eventfd,它主要用于进程或线程间通信(如通知/等待机制的实现)。
1 2 3 4 5 #include <sys/eventfd.h> int eventfd (unsigned int initval, int flags)
eventfd 支持的操作:
read
write
select / poll / epoll
eventfd 是专门用于事件通知的文件描述符(fd)。它创建一个 eventfd 对象,eventfd 对象不仅可以用于进程间的通信,还能用于用户态和内核态的通信。eventfd 对象在内核中包含了一个计数器,该计数器是 64 位的无符号整数(uint64_t),计数不为零是有可读事件发生,read 之后计数会清零,write 则会递增计数器。
看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include <sys/eventfd.h> #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <stdint.h> #define handle_error(msg) \ do { perror(msg); exit(EXIT_FAILURE); } while (0) int main (int argc, char *argv[]) int efd, j; uint64_t u; ssize_t s; if (argc < 2 ) { fprintf (stderr, "Usage: %s <num>...\n" , argv[0 ]); exit (EXIT_FAILURE); } efd = eventfd (10 , 0 ); if (efd == -1 ) handle_error ("eventfd" ); switch (fork()) { case 0 : for (j = 1 ; j < argc; j++) { printf ("Child writing %s to efd\n" , argv[j]); u = strtoull (argv[j], NULL , 0 ); s = write (efd, &u, sizeof (uint64_t )); if (s != sizeof (uint64_t )) handle_error ("write" ); sleep (1 ); } printf ("Child completed write loop\n" ); exit (EXIT_SUCCESS); default : sleep (2 ); for (int idx = 2 ; idx < argc; ++idx) { printf ("Parent about to read\n" ); s = read (efd, &u, sizeof (uint64_t )); if (s != sizeof (uint64_t )) handle_error ("read" ); printf ("Parent read %llu (0x%llx) from efd\n" , (unsigned long long ) u, (unsigned long long ) u); sleep (1 ); } exit (EXIT_SUCCESS); case -1 : handle_error ("fork" ); } }
eventfd 的封装 类图(这个 MyTask 就是 CppNote4 里面的):
代码:https://github.com/dropsong/CPP_Code_Eaxmple/tree/master/EventFd
Reactor模型(V4) 注意,这里我们将上一张图片里的 EventFd 类揉碎了放进 EventLoop 类中:
代码:https://github.com/dropsong/CPP_Code_Eaxmple/tree/master/Reactor_v4
很多注释都在代码里面。
注意:在 Reactor_v4 的 TestTcpServer.cc 代码中:
1 gPool->addTask (std::bind (&MyTask::process, task));
并没有传递 task 的地址,这与之前的介绍不一样,这是为什么呢?
我们实验一下,发现如果用 & 取地址,运行时会报 core dumped.
这是因为 task 对象的生命周期已经结束(而且它们会分属不同的线程):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void onMessage (const TcpConnectionPtr &con) string msg = con->receive (); cout << ">>recv msg from client: " << msg << endl; MyTask task (msg, con) ; gPool->addTask (std::bind (&MyTask::process, task)); }
而不取地址的时候,会做一个值传递(拷贝)。
这是 bind() 函数本身的特性,之前只是没有提:
Reactor模型(V5) 在 v4 模型中,还有一些不足:使用了全局变量。
v4 中我们之所以使用全局变量,是暂时没有什么手段处理生命周期的问题。现在我们重新考虑:
代码如下:https://github.com/dropsong/CPP_Code_Eaxmple/tree/master/Reactor_v5
代码相较于 v4 的变动是:
TestTcpServer.cc 变为 EchoServer.h ,其中的封装技巧值得注意。测试文件 testFile.cc 。
定时器 timerfd timerfd 是 Linux 提供的一个定时器接口。这个接口基于文件描述符 ,通过文件描述符的可读事件进行超时通知,所以能够被用于 select/poll/epoll 的应用场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <sys/timerfd.h> int timerfd_create (int clockid, int flags) ;int timerfd_settime (int fd, int flags, const struct itimerspec *new_value, struct itimerspec *old_value) ;struct timespec { time_t tv_sec; long tv_nsec; }; struct itimerspec { struct timespec it_interval ; struct timespec it_value ; };
考虑封装其功能如下:
代码:https://github.com/dropsong/CPP_Code_Eaxmple/tree/master/TimerFd
TimerFd 自然也可以用在 Reactor 的代码中,只不过未必好。
eventfd 与 timerfd 都可以用于线程间通信。eventfd 是让 A 线程主动唤醒 B 线程进行操作,而 timerfd 是让 B 线程被定时唤醒。
最短编辑距离 算法原理 本节内容参考: NLP 笔记(三):最短编辑距离
首先引入提出算法的动机。
1)如何衡量两个字符串有多相似?例如,我们需要实现拼写纠正 :用户键入“graffe”,以下哪个最接近?
2)计算生物学:
编辑距离(Edit Distance) :两个字符串之间的最短编辑距离是指将一个字符串变换为另一个需要的编辑操作(插入(Insertion),删除(Deletion),替换(Substitution))的最小数量。
例如:
注意:
如果每个操作的代价值为 1,则此两个字符串之间的距离为 5
如果替换操作的代价值为 2,则距离为 8
该问题可以动态规划求解。
现有长为 n 的字符串 X,长为 m 的字符串 Y .
定义: D(i, j) 为 X[1...i](X 的前 i 个字符)和 Y[1...j](Y 的前 j 个字符)的最短编辑距离。
注意:这里下标是从 1 开始的。
那么我们所求的就是 D(n, m) .
边界条件: D(i, 0) = i,D(0, j) = j .
对边界条件的解释:
递推公式(替换操作代价为2):
递推公式(替换操作代价为1):
对递推公式的解释,一图胜千言:
对应的 leetcode 题目: edit-distance
到这里的原理已经足够我们应用了,但是我们继续拓展一下。
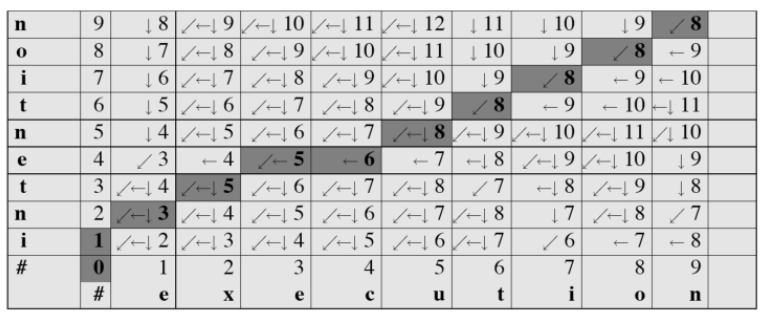
计算对齐(Computing alignments) :我们经常需要将两个字符串的每个字符彼此对齐,这可以通过保持“回溯(backtrace)”来做到:
根据上图回溯,得到两个字符串和它们之间的对齐,见图 76-11.
一点微小的技巧:*填充在 76-11 上面还是下面取决与 76-13 黑线是横着走还是竖着走。
加权最短编辑距离 :嗯,就是加个权。
为什么要在计算中加权?
拼写纠正:有些字母比其他字母更容易输入错
生物学:某些类型的删除或插入更有可能发生
算法实现:
应用 作为搜索引擎功能的很小一部分,我们试图实现一个中英文混合的最小编辑距离算法。
UTF8 编码规则:
于是,可以写出如下函数求一个字符在 UTF-8 编码中占据的字节数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 size_t nBytesCode (const char ch) if (ch & (1 << 7 )) { int nBytes = 1 ; for (int idx = 0 ; idx != 6 ; ++idx) { if (ch & (1 << (6 - idx))) { ++nBytes; } else break ; } return nBytes; } return 1 ; }
实际上,下面这份代码不仅支持中英文混合,只要是 UTF-8 就行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 #include <string> #include <iostream> using std::cout;using std::endl;using std::string; size_t nBytesCode (const char ch) std::size_t length (const std::string &str) ;int editDistance (const std::string & lhs, const std::string &rhs) void test0 () string s1 = "abcd" ; string s2 = "中国" ; for (auto & ch : s2) { cout << ch; } cout << endl; cout << "s2[1]: " << s2[1 ] << endl; cout << endl; cout << "s1.size() : " << s1.size () << endl; cout << "s2.size() : " << s2.size () << endl; string s3 = s2.substr (0 , 3 ); cout << "s3.size(): " << s3.size () << endl; cout << "s3: " << s3 << endl; string s4 = s2.substr (1 , 3 ); cout << "s4.size(): " << s4.size () << endl; cout << "s4: " << s4 << endl; string s5 = "abc中国" ; cout << "s5.size(): " << s5.size () << endl; cout << "s5.length: " << length (s5) << endl; cout << "s2与s5的最小编辑距离: " << editDistance (s2, s5) << endl; string s6 = "今夜は月が綺麗ですね" ; string s7 = "今夜月綺麗,有道理" ; cout << "s6.size(): " << s6.size () << endl; cout << "s6.length: " << length (s6) << endl; cout << "s7.size(): " << s7.size () << endl; cout << "s7.length: " << length (s7) << endl; cout << "s6与s7的最小编辑距离: " << editDistance (s6, s7) << endl; } int main (void ) test0 (); return 0 ; } size_t nBytesCode (const char ch) if (ch & (1 << 7 )) { int nBytes = 1 ; for (int idx = 0 ; idx != 6 ; ++idx) { if (ch & (1 << (6 - idx))) { ++nBytes; } else break ; } return nBytes; } return 1 ; } std::size_t length (const std::string &str) std::size_t ilen = 0 ; for (std::size_t idx = 0 ; idx != str.size (); ++idx) { int nBytes = nBytesCode (str[idx]); idx += (nBytes - 1 ); ++ilen; } return ilen; } int triple_min (const int &a, const int &b, const int &c) return a < b ? (a < c ? a : c) : (b < c ? b : c); } int editDistance (const std::string & lhs, const std::string &rhs) size_t lhs_len = length (lhs); size_t rhs_len = length (rhs); int editDist[lhs_len + 1 ][rhs_len + 1 ]; for (size_t idx = 0 ; idx <= lhs_len; ++idx) { editDist[idx][0 ] = idx; } for (size_t idx = 0 ; idx <= rhs_len; ++idx) { editDist[0 ][idx] = idx; } std::string sublhs, subrhs; for (std::size_t dist_i = 1 , lhs_idx = 0 ; dist_i <= lhs_len; ++dist_i, ++lhs_idx) { size_t nBytes = nBytesCode (lhs[lhs_idx]); sublhs = lhs.substr (lhs_idx, nBytes); lhs_idx += (nBytes - 1 ); for (std::size_t dist_j = 1 , rhs_idx = 0 ; dist_j <= rhs_len; ++dist_j, ++rhs_idx) { nBytes = nBytesCode (rhs[rhs_idx]); subrhs = rhs.substr (rhs_idx, nBytes); rhs_idx += (nBytes - 1 ); if (sublhs == subrhs) { editDist[dist_i][dist_j] = editDist[dist_i - 1 ][dist_j - 1 ]; } else { editDist[dist_i][dist_j] = triple_min ( editDist[dist_i][dist_j - 1 ] + 1 , editDist[dist_i - 1 ][dist_j] + 1 , editDist[dist_i - 1 ][dist_j - 1 ] + 1 ); } } } return editDist[lhs_len][rhs_len]; }
Stop words 本节内容转载自: What are Stop Words?
What are Stop Words When working with text mining applications, we often hear of the term “stop words” or “stop word list” or even “stop list”. Stop words are basically a set of commonly used words in any language, not just English.
The reason why stop words are critical to many applications is that, if we remove the words that are very commonly used in a given language, we can focus on the important words instead. For example, in the context of a search engine, if your search query is “how to develop information retrieval applications”, If the search engine tries to find web pages that contained the terms “how”, “to” “develop”, “information”, ”retrieval”, “applications” the search engine is going to find a lot more pages that contain the terms “how”, “to” than pages that contain information about developing information retrieval applications because the terms “how” and “to” are so commonly used in the English language. If we disregard these two terms, the search engine can actually focus on retrieving pages that contain the keywords: “develop” “information” “retrieval” “applications” – which would bring up pages that are actually of interest. This is just the basic intuition for using stop words.
Stop words can be used in a whole range of tasks and here are a few:
Supervised machine learning – removing stop words from the feature space
Clustering – removing stop words prior to generating clusters
Information retrieval – preventing stop words from being indexed
Text summarization- excluding stop words from contributing to summarization scores & removing stop words when computing ROUGE scores
Types of Stop Words Stop words are generally thought to be a “single set of words”. It really can mean different things to different applications. For example, in some applications removing all stop words right from determiners (e.g. the, a, an) to prepositions (e.g. above, across, before) to some adjectives (e.g. good, nice) can be an appropriate stop word list. To some applications however, this can be detrimental. For instance, in sentiment analysis removing adjective terms such as ‘good’ and ‘nice’ as well as negations such as ‘not’ can throw algorithms off their tracks. In such cases, one can choose to use a minimal stop list consisting of just determiners or determiners with prepositions or just coordinating conjunctions depending on the needs of the application.Examples of minimal stop word lists that you can use:
Determiners – Determiners tend to mark nouns where a determiner usually will be followed by a nounCoordinating conjunctions – Coordinating conjunctions connect words, phrases, and clausesPrepositions – Prepositions express temporal or spatial relations
In some domain specific cases, such as clinical texts, we may want a whole different set of stop words. For example, terms like “mcg” “dr” and “patient” may have less discriminating power in building intelligent applications compared to terms such as ‘heart’ ‘failure’ and ‘diabetes’. In such cases, we can also construct domain specific stop words as opposed to using a published stop word list.
应用 对于我们的应用而言,上面的介绍已经足够了,更进一步的了解,在转载文章中查看。
这个 stop words list 可以上网找一个合适的,亦可自己制作(?)。
boost::regex 项目会用到 boost::regex 库,标准库的实现有 bug (截至 12.2.0),而 boost::regex 可以正常处理。
在 Ubuntu/Debian 上安装:
1 sudo apt-get install libboost-regex-dev
一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> #include <boost/regex.hpp> #include <string> int main () std::string text = "<description>This is a description.</description>\n<content>This is the\ncontent with new lines.</content>" ; boost::regex re_description ("<description>([\\s\\S]*?)</description>" ) ; boost::regex re_content ("<content>([\\s\\S]*?)</content>" ) ; boost::smatch match_description; boost::smatch match_content; std::string description; std::string content; if (boost::regex_search (text, match_description, re_description)) { if (match_description.size () > 1 ) { description = match_description[1 ].str (); std::cout << "Description 内容: " << description << std::endl; } } else { std::cout << "没有匹配到 <description> 内容。" << std::endl; } if (boost::regex_search (text, match_content, re_content)) { if (match_content.size () > 1 ) { content = match_content[1 ].str (); std::cout << "Content 内容: " << content << std::endl; } } else { std::cout << "没有匹配到 <content> 内容。" << std::endl; } return 0 ; }
编译时需要编译选项:
1 g++ 你的代码.cc -lboost_regex
另一个使用 boost::regex 的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> #include <string> #include <boost/regex.hpp> std::string findSentenceWithKeyword (const std::string& content, const std::string& keyword) { std::string regexPattern = "(.{0,13})(" + keyword + ")(.{0,13})" ; boost::regex pattern (regexPattern) ; boost::smatch match; if (boost::regex_search (content, match, pattern)) { return "..." + match.str (1 ) + match.str (2 ) + match.str (3 ) + "..." ; } return "" ; } int main () std::string content = "这是一个简单的例子,内容中包含了一个关键字。The keyword is important. 关键字非常重要。" ; std::string keyword = "keyword" ; std::string result = findSentenceWithKeyword (content, keyword); if (!result.empty ()) { std::cout << "Found sentence: " << result << std::endl; } else { std::cout << "Keyword not found in the content." << std::endl; } return 0 ; }
思路草图
离线部分 词频统计、编制索引不提。值得注意的是处理中文时会需要:
1 2 3 4 5 string trim (const string& str) { size_t first = str.find_first_not_of (" \n\r\t" ); size_t last = str.find_last_not_of (" \n\r\t" ); return (first == string::npos || last == string::npos) ? "" : str.substr (first, last - first + 1 ); }
在编制网页库时,需要根据不同的 xml 文件格式编写一些特别处理的代码,有点麻烦。时不时遇到 core dump ,这大概是指针空了,需要 gdb 看看哪里出了问题,有的时候还需要深入到 xml 文件里看看,这大概率是这个 xml 文件写的很飘。
另外,编制网页库时还会需要 Simhash 去重,直接使用别人的代码:yanyiwu/simhash 。关于 Simhash 的原理(若下面这个链接挂了,可以去 https://archive.ph/ 查找):
https://www.cnblogs.com/maybe2030/p/5203186.html
接着是编写偏移库,会用到 tellg() 之类的函数。
最后编写倒排索引,使用 TF-IDF 算法。
该算法的目标是:
某词在文档中的出现次数越多,权重越大
在整个网页库中的出现次数越多,权重越小
定义:
词语的权重为:
一篇文档包含多个词语,其权重为 w1, w2, …, wn,对这些权重系数归一化:
在线部分 首先,我们已经有了 Reactor 模型(V5)的代码,直接把它拿过来,就是一个 echo 服务器,添加业务逻辑的代码,就可以是想要的 SearchEngine server 代码了。
业务逻辑有两块,关键词推荐和网页搜索。server 要怎么知道 client 发过来的请求是关键字推荐还是网页搜索呢?可见,我们需要定义消息的格式。简单起见,消息分为如下两种:
1 2 3 1 somemsg # 关键字推荐,somemsg 为具体内容 2 somemsg # 网页搜索 # 其他格式,服务器应该返回 "format error !"
关键字推荐 关键字搜索应该怎么做呢?
我们先额外考虑一下缓存的情况。如果 client 发过来的查询已经在缓存中,直接将缓存中的数据取出。若不在缓存中,走完流程后还需要将这次查询和查询的结果保存在缓存中。
纯英文的情况,比如“hello”,我们可以把字符串拆开,h e l o ,对于每一个字符,在索引库(索引是词频库的索引)里面查找其对应的集合,得到包含这个字母的单词在词频库里面的行号。对这些集合取并集。
为什么是并集呢?因为我们要求的是与 hello 相似的单词,这允许出现这四个字母以外的字母。我们可以先取并集得到一个很大的集合(里面是词频库的行号),然后根据这个行号得到具体的单词和频率。这样得到的单词至少有一个字母和 hello 相同(打倒一大片,拾取一小撮)。
我们仍然要求得到的结果和 hello 有些相似,相似程度由最短编辑距离衡量。过滤掉相似度不足的单词(不妨设编辑距离大于 3 就认为不相似),剩下的就是合法的单词和词频。我们会得到如下的数据:
1 {单词, dist(编辑距离), freq(词频)}
这种形式的数据可能很多,而我们只需要五六个就差不多了。为此需要评价到底哪个单词更好,我们可以将这种形式的数据放在 struct 中,然后定义 < :
dist 小的更相似。这符合直觉。
dist 相同的情况下,freq 越大,就提高该单词的优先级。
定义了结构体的比较方法之后,就可以把这些数据放在优先队列中,这样取数据的时候只要 pop 一定数量的元素即可。
那么,中文的情况呢?其实也是一样的做法。
中英文混合推荐呢?将中文和英文分开,分别做一遍中文和英文的关键字推荐流程即可。
网页搜索 同样先考虑一下缓存的情况。
我们如法炮制,按照关键字推荐的方法做缓存,这样会有什么问题呢?
假设我们有两条查询:
因为我们将数据放在缓存中的时候,是将 cat 和对应的结果放进去的,这样没法区分开。我们改变放入缓存的策略:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include "useRedis.h" #include "myRedis.h" #include <memory> using std::unique_ptr;string findInCache (const string& A, string flag) unique_ptr<MyRedis> pRedis (new MyRedis()) ; if (!pRedis->connect ("127.0.0.1" , 6379 )){ cerr << "connect error ! " << endl; } return pRedis->get ("flAg" +flag+"xD" +A); } void putInCache (const string& A, const string& B, string flag) unique_ptr<MyRedis> pRedis (new MyRedis()) ; if (!pRedis->connect ("127.0.0.1" , 6379 )){ cerr << "connect error ! " << endl; return ; } pRedis->set ("flAg" +flag+"xD" +A, B); }
处理查询请求时,对于 client 发来的搜索词,将它们视为一篇文档 X,计算出每个关键词的权重系数,这就要先进行 jieba 分词。
此处的权重系数,并不能完全按照 TF-IDF 算法。因为这里词语的权重仅是在该查询语句中的权重,计算词频 Wi 即可,然后归一化:
将其组成一个向量(w1, w2, …,wn),该向量作为基准向量 Base .
通过倒排索引表查找包含所有关键字的网页,只要其中有一个查询词不在索引表中,就认为没有找到相关的网页。在这个过程中,不仅要把一个个词语对应的 docid 放在放在 vector<set<int>> 中,还要将某个 docid 里某个分词的 TF-IDF 权重放在 map<pair<int, string>, double> 中。
将得到的 set 取交集,对于每一篇文章,计算它与 base 的余弦相似度。
将搜索结果填充标题、链接、摘要,并按余弦相似度排序。
如何生成摘要信息?见 boost::regex 部分的代码。
后日谈 没什么可谈的。
代码链接:见 github 仓库。











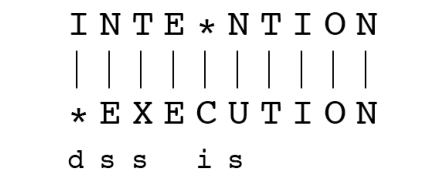






 Thanks ᗜ ‸ ᗜ
Thanks ᗜ ‸ ᗜ











